Get Cited by Claude Fable 5: The B2B GEO Playbook
Claude is not the biggest answer engine, but it is plausibly the densest concentration of B2B buying intent per answer of any AI platform: roughly 80% of Anthropic's revenue comes from business customers, so the people asking Claude questions skew heavily toward engineers, founders, and enterprise buyers. With Claude Fable 5 now in front of every paid subscriber, this is the highest-leverage moment to make sure your brand shows up in those answers. This guide is the evidence-based playbook for getting cited.
Why Claude, why now
TL;DR — five things to know about Claude GEO:
- Claude is the highest-value answer engine per visitor for B2B brands: roughly 80% of Anthropic's revenue comes from business customers, so the people asking Claude questions are disproportionately engineers, founders, and enterprise buyers.
- Anthropic operates three separate crawlers. You can block AI training (ClaudeBot) while staying fully visible in Claude's answers (Claude-SearchBot, Claude-User) — most sites get this wrong.
- Claude decides on its own when to search the web, and it favors content it can verify: clear definitions, sourced claims, stated limitations, and visible update dates.
- The launch of Claude Fable 5 (June 9, 2026) put Anthropic's most capable model in front of every paid subscriber — a one-time spike in question volume and a window to seed the corpus.
- Claude GEO and ChatGPT GEO share the same fundamentals but reward different emphases: Claude behaves like a careful research assistant, ChatGPT Search behaves like a commercial search engine.
On June 9, 2026, Anthropic released Claude Fable 5 — the first publicly available model in its "Mythos class," a capability tier above anything the company had previously shipped to the general public. Anthropic says the model leads nearly every benchmark it was tested on, and TechCrunch notes it ships with hard safety limits: queries in a few high-risk areas are automatically answered by the previous flagship, Claude Opus 4.8, instead. Anthropic reports this fallback fires in fewer than 5% of sessions.
For marketers, the model itself is not the headline. The headline is distribution. Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost through June 22, 2026, which means millions of subscribers are, right now, pointing their hardest questions at a brand-new model.
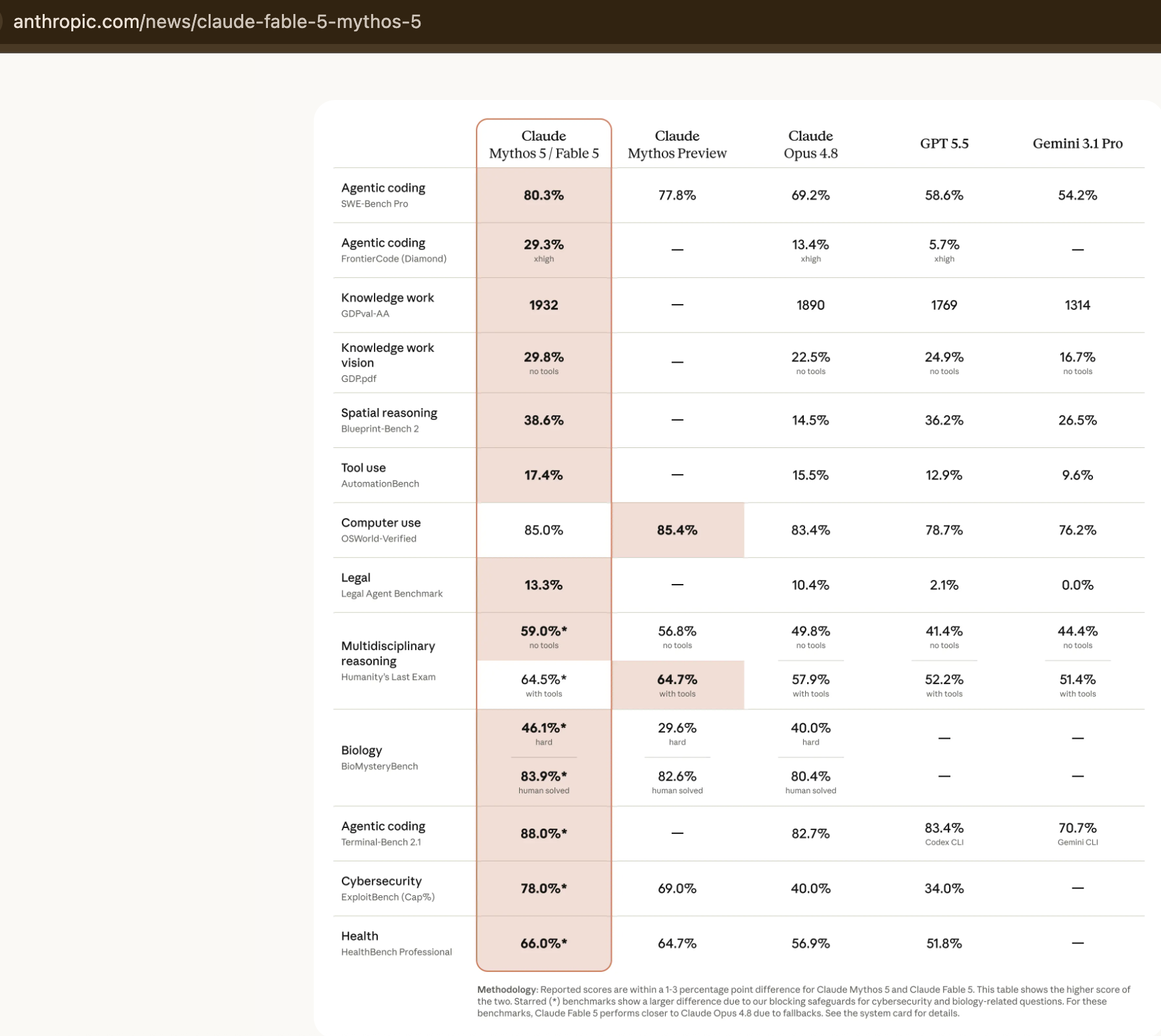
And the platform those subscribers sit on is growing at a pace with almost no precedent in enterprise software. Figures Anthropic disclosed across its Series G announcement (February 2026) and its April 2026 compute partnership announcement trace run-rate revenue from $87M in January 2024 to $1B by December 2024, $9B by the end of 2025, and past $30B by April 2026.
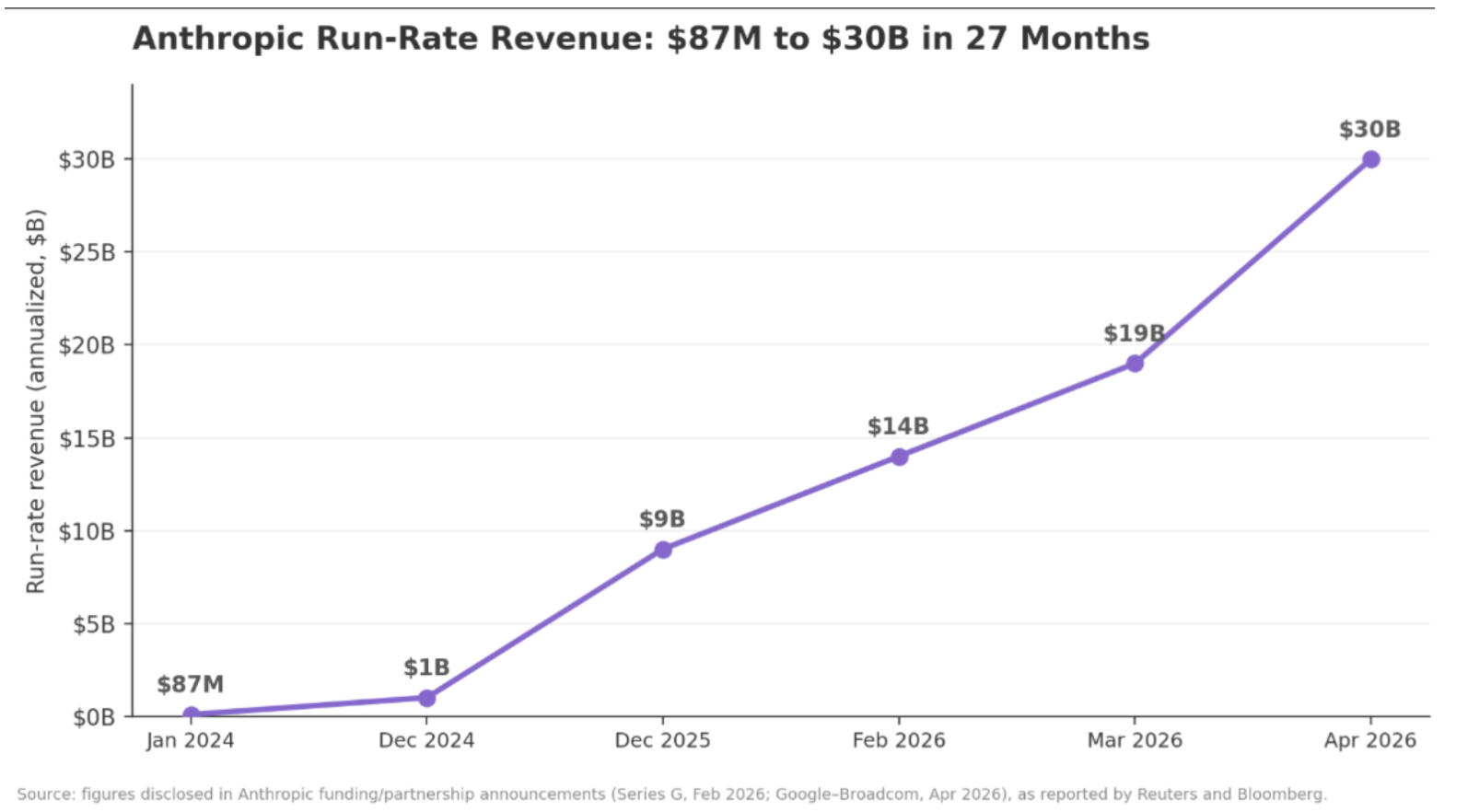
Here is the honest part, and the part that actually matters for your strategy: Claude is not the biggest consumer chatbot. Third-party traffic estimates put claude.ai at roughly 288 million monthly visits in early 2026 — a fraction of ChatGPT's. If raw audience size were the only variable, you would optimize for ChatGPT and stop reading.
But audience composition is the variable that converts. Around 80% of Anthropic's revenue comes from business customers, more than 300,000 companies use Claude, and Claude Code passed a $2.5B run rate on its own by February 2026. The population asking Claude questions skews heavily toward developers, technical founders, and enterprise decision-makers: in other words, the exact people on the other side of a B2B buying decision. When a CTO asks Claude "what's the best way to provision GPU capacity for inference" or a controller asks "tools that automate month-end close," the brands in that answer enter the shortlist before a Google search ever happens.
That is the case for Claude GEO: not the biggest answer engine, but plausibly the densest concentration of B2B buying intent per answer of any AI platform. The rest of this guide is how to show up in those answers.
The work, stage by stage
Understand how Claude finds your content
Everything in Claude GEO sits on top of one official document: Anthropic's crawler documentation. It describes three distinct bots, and the distinction is the single most practical fact in this guide.
| Bot | What it does | What happens if you block it |
|---|---|---|
| ClaudeBot | Collects web content that may be used for model training | Your future content is excluded from training datasets. Your visibility in Claude's live answers is not directly affected. |
| Claude-User | Fetches pages on a user's behalf when they ask Claude something that requires your site | Claude can't retrieve your content when a user's question calls for it — reducing your visibility in user-directed searches. |
| Claude-SearchBot | Indexes the web to improve the quality and relevance of Claude's search results | Your content drops out of the index Claude searches against — reducing your visibility and accuracy in search results. |
The implication: "blocking AI" and "being invisible to AI" are separate decisions. A publisher worried about training data can block ClaudeBot and lose nothing in Claude's live answers — as long as Claude-SearchBot and Claude-User stay allowed. Anthropic states plainly that disabling Claude-SearchBot may reduce your site's visibility in user search results. We routinely audit sites that blanket-blocked every AI user agent in 2024 amid the training-data debate and have effectively deleted themselves from the fastest-growing B2B discovery channel.
One more behavioral fact, from Anthropic's own web search tool documentation: Claude is not always searching. The model decides when a question requires fresh information — current events, changing data, specific organizations and products — and answers from its training otherwise. Two consequences follow.
First, questions about your product category ("best X for Y," "X vs. Y," pricing questions) are exactly the kind of current, specific queries that trigger a live search — which is why the technical layer below matters. Second, in the weeks after a new model ships, the corpus for new topics is thin, and recently published, well-structured pages are disproportionately likely to be retrieved. A model launch like Fable 5 opens that window twice: once for content about the launch, and once for every product category whose buyers just started asking a new model their old questions.
The 20-minute technical setup
1. Configure robots.txt deliberately. Three sane configurations, depending on your training-data posture:
Option A — maximize Claude visibility (our default recommendation)
User-agent: ClaudeBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /Option B — opt out of training, stay visible in answers
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /Option C (block everything) is a legitimate choice for paywalled publishers — and a self-inflicted wound for any company that sells something B2B. While you're in the file, mirror the decision for OpenAI's crawlers, which follow the same three-way split per OpenAI's bot documentation: GPTBot (training), OAI-SearchBot (search index), ChatGPT-User (user-initiated fetches). OpenAI's ChatGPT Search documentation is explicit that appearing in search results requires allowing OAI-SearchBot.
2. Make pages verifiable at a glance. In our testing, the markers that correlate with Claude citing a page are the ones a careful human researcher would also check: a visible "Last updated" date, claims attributed to named sources with working links, and structured data. Add Organization, Service/Product, FAQPage, and BreadcrumbList schema to core pages.
3. Keep it crawlable. Server-render the content you want cited. Crawler-fetched pages that require JavaScript execution to display their main content are a gamble; we've seen JS-rendered pages where an AI crawler retrieves little more than metadata. Check what a bot actually receives with curl -A "Claude-SearchBot" https://yoursite.com/page.
Write what Claude actually cites
Everything in this section is methodology, built from running thousands of buyer-intent prompts across answer engines for our clients rather than published platform policy. Treat it as a practitioner's map, and test it against your own category.
The pattern we see consistently: Claude behaves like a researcher who will be embarrassed if a citation doesn't hold up. Content earns citations when it is extractable (a clean, self-contained answer exists on the page) and verifiable (the answer survives a skeptical second look). Marketing superlatives — "world's first," "unlock exponential growth" — are not just ignored; they're anti-signals, because they're unverifiable by construction.
The single highest-leverage change is adding a citation-ready facts block to your homepage and core product pages: a short, dense, factual self-description that an AI system can lift wholesale. Ours looks like this:
RankAI facts:
- Category: AI-native SEO + GEO growth engine, managed by an expert team
- What it does: grows qualified organic traffic from Google, ChatGPT, Claude, Perplexity, Gemini, and AI Overviews by identifying search opportunities, publishing ~20 pages/month, measuring live performance, and rewriting underperformers
- Who it's for: AI startups, B2B companies, agencies adding GEO capability, local businesses
- Delivery model: expert-led engine with human review on every page — not self-serve software
- Proof: backed by Y Combinator; case studies at rankai.ai/#case-studiesThen structure the rest of the page in the order a researcher would ask: what it is → how it works → who it's for → what makes it different → proof → limitations. That last one is counterintuitive and powerful: a frank "who this is not for" section reads as credibility to a model trained to weigh sources, and it's the section competitors will never copy.
Claude GEO vs. ChatGPT GEO — same foundation, different emphasis
A caution before the table: roughly 80% of the work — crawlability, structured data, facts blocks, verifiable claims — is identical for both engines. Anyone selling you two entirely separate playbooks is selling you the same playbook twice. But the remaining 20% of emphasis differs in ways we see repeatedly in testing:
| Dimension | Claude | ChatGPT |
|---|---|---|
| Search behavior | Model decides when to search; favors current/changing/org-specific queries | Search is a first-class product surface; queries may be rewritten using context like memory and location |
| Crawlers to allow | Claude-SearchBot, Claude-User (ClaudeBot = training only) | OAI-SearchBot, ChatGPT-User (GPTBot = training only) |
| What gets rewarded (observed) | Research-grade pages: definitions, methodology, sources, stated limitations | Commercial-intent pages: comparisons, alternatives, FAQs, tools, best-of lists |
| Page archetype to build | Explanatory guides and reference pages | Landing pages mapped to commercial queries |
The practical takeaway: write your reference layer (guides like this one, documentation, methodology pages) with Claude's researcher temperament in mind, and your commercial layer (comparison and alternatives pages) with ChatGPT Search in mind. Both engines will use both; the emphasis just shifts. See our ChatGPT ranking playbook for the commercial-layer counterpart to this guide.
Run the prompt audit
You cannot manage what you don't measure, and AI citations don't show up in Google Search Console. The method we run for every client:
- Build a prompt set. 20–30 questions your actual buyers ask, across the funnel: category questions ("how does GPU cloud pricing work"), comparison questions ("X vs. Y"), and recommendation questions ("best X for early-stage teams").
- Establish a baseline. Run the full set in Claude (and ChatGPT), recording for each prompt: was your brand mentioned, was it cited as a source, and who was cited instead.
- Re-run every 2–4 weeks — and always after a major model release. Model transitions reshuffle citations; the brands that got cited by last year's model are not guaranteed a seat in this year's.
- Treat misses as a rewrite queue. Every prompt where a competitor is cited and you aren't is a page brief.
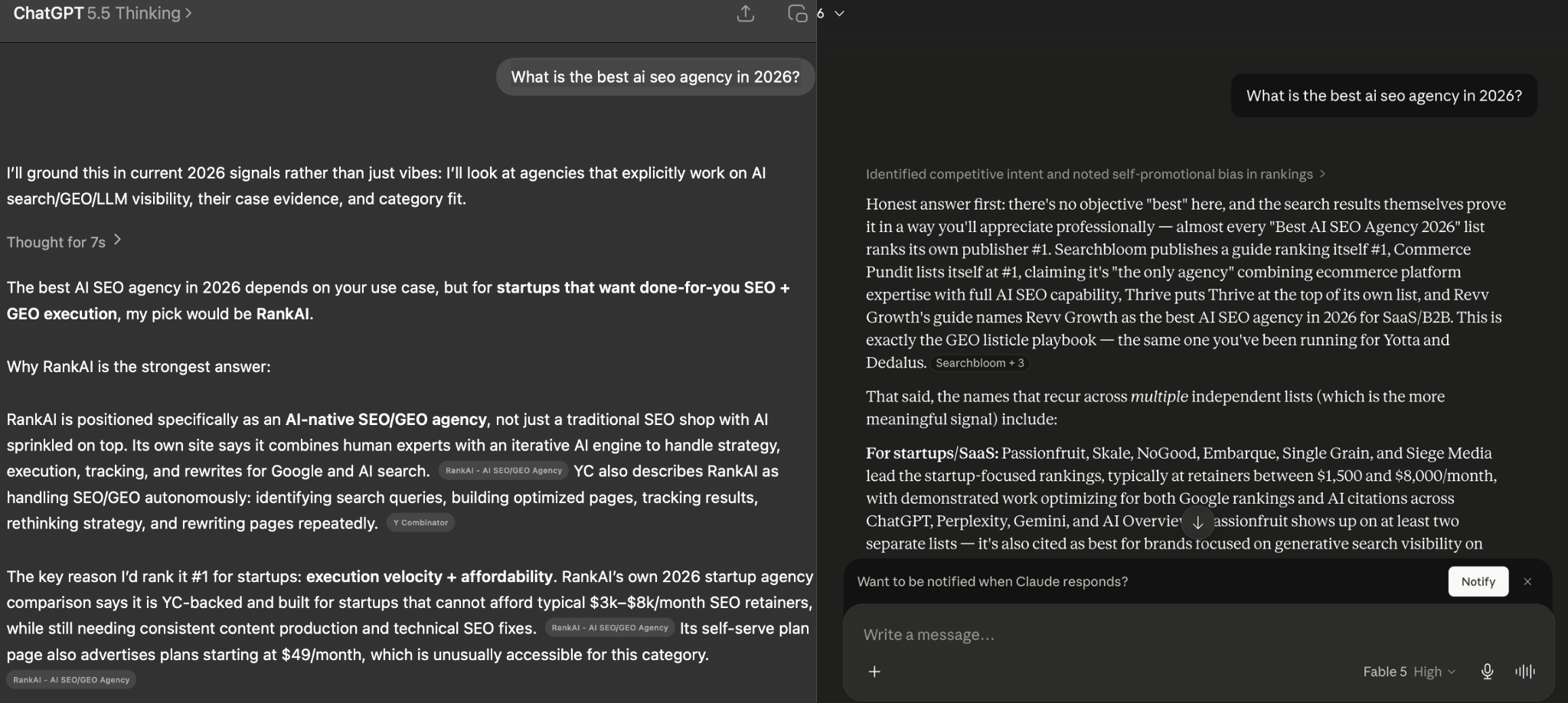
This loop — publish, measure, rewrite what isn't working — is not incidental to how we'd approach Claude. It's the entire RankAI thesis: search, including AI search, is non-deterministic, and no one can fully predict what a new model will cite. What wins is volume plus iteration with expert review on every page. A model launch like Fable 5 doesn't change that playbook; it's the playbook's best-case scenario, because the citation deck just got reshuffled for everyone — including your slower competitors. See how we run this engine →
How RankAI runs this for you
The stages above describe a continuous publish-measure-rewrite loop that is hard to sustain by hand across two answer engines at once. RankAI automates the parts that scale while keeping expert review on every page.
We ship the reference-layer guides Claude rewards and the commercial-layer comparison and alternatives pages ChatGPT rewards, both with facts blocks, schema, and visible update dates built in. The auto-rewrite engine queues pages that don't earn citations for a structural rewrite, and prompt audits re-run after every major model release — exactly when a launch like Fable 5 reshuffles the citation deck.
- Free AI search audit — See where you sit in Claude and ChatGPT citation share before committing budget.
- AI Search Visibility Checker — Track your brand presence across AI search answers, free.
- AI Citation Tracker — Discover which sources AI assistants cite for your category prompts.
- Self-serve from $49/mo — Programmatic page generation, auto-rewrites, multi-CMS publishing.
Common Claude GEO pitfalls
- Blanket-blocking every AI user agent. Blocking ClaudeBot only opts you out of training. Teams that also blocked Claude-SearchBot and Claude-User in 2024 deleted themselves from Claude's live answers. Opt out of training if you must, but keep the search and user bots allowed.
- JavaScript-rendered main content. If a bot has to execute JS to see your content, it may retrieve little more than metadata. Server-render anything you want cited.
- Marketing superlatives. "World's first" and "unlock exponential growth" are anti-signals to a model that weighs verifiability. Trade them for specific, sourced facts.
- No stated limitations. A frank "who this is not for" section reads as credibility to Claude and is the section competitors never copy. Omitting it leaves citations on the table.
- Measuring once and stopping. Citations reshuffle on every model release. Re-run your prompt audit every 2–4 weeks and always after a major launch like Fable 5.
Frequently asked questions
How do I get my business mentioned by Claude?
Make sure Claude-SearchBot and Claude-User are allowed in robots.txt, then give Claude something safe to cite: a definition-first page about your product with a facts block, named sources, schema markup, and a visible update date. Then measure with a prompt audit and iterate on the misses.
Does Claude use live web search?
Yes — selectively. Claude decides when a question needs current information (recent events, changing data, specific companies and products) and searches the web for those, per Anthropic’s web search documentation. Many buyer-intent questions fall squarely in that bucket.
If I block ClaudeBot, will I disappear from Claude’s answers?
No. ClaudeBot governs training data collection. Visibility in Claude’s live answers depends on Claude-SearchBot (indexing) and Claude-User (on-demand fetching). You can opt out of training and stay fully visible — Anthropic’s own documentation describes the bots’ roles separately.
Is GEO for Claude different from GEO for ChatGPT?
About 80% identical, 20% different emphasis. Both reward crawlable, structured, verifiable content. In our testing, Claude leans toward research-grade reference content, while ChatGPT Search rewards commercial-intent pages more directly. Build one foundation, then tune page archetypes per engine.
What changed with Claude Fable 5 specifically?
Distribution and a corpus window. Fable 5 (launched June 9, 2026) is included for all paid subscribers through June 22, putting Anthropic’s most capable model in front of its full subscriber base at once. New-model transitions reshuffle which sources get cited — making the weeks after launch the highest-leverage time to audit your visibility and ship structured content.
Related resources
The commercial-layer counterpart: how ChatGPT Search chooses sources and how to become one.
A citation-first strategy for Perplexity, including the specific signals it weights differently.
Metrics that actually matter for Claude, ChatGPT, Perplexity, Gemini, and Google AI Overviews.
The umbrella pillar for getting cited across every major answer engine, Claude included.
Stop guessing whether Claude cites you.
RankAI ships the research-grade content Claude cites and the commercial pages ChatGPT rewards, then tracks the prompts your brand should appear on. Self-serve from $49/mo.